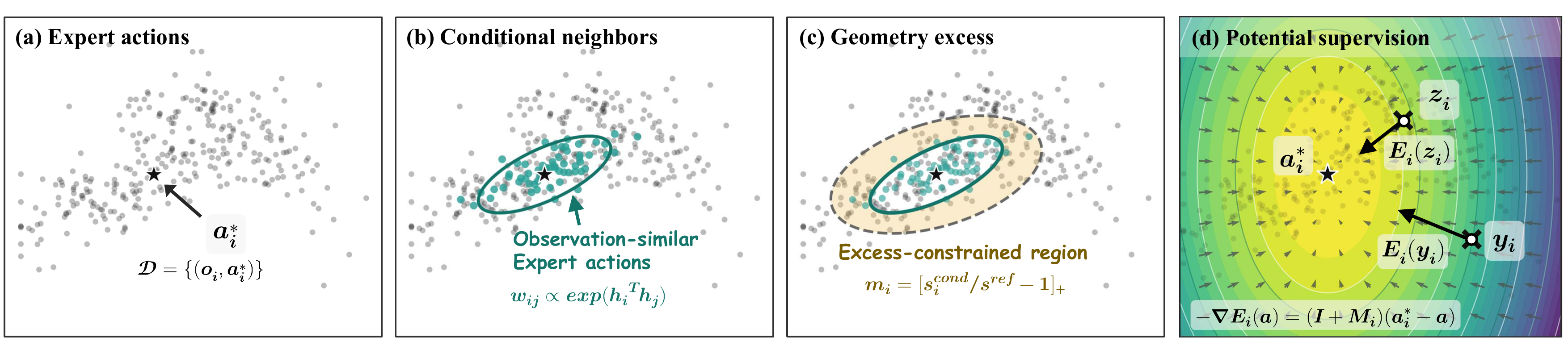
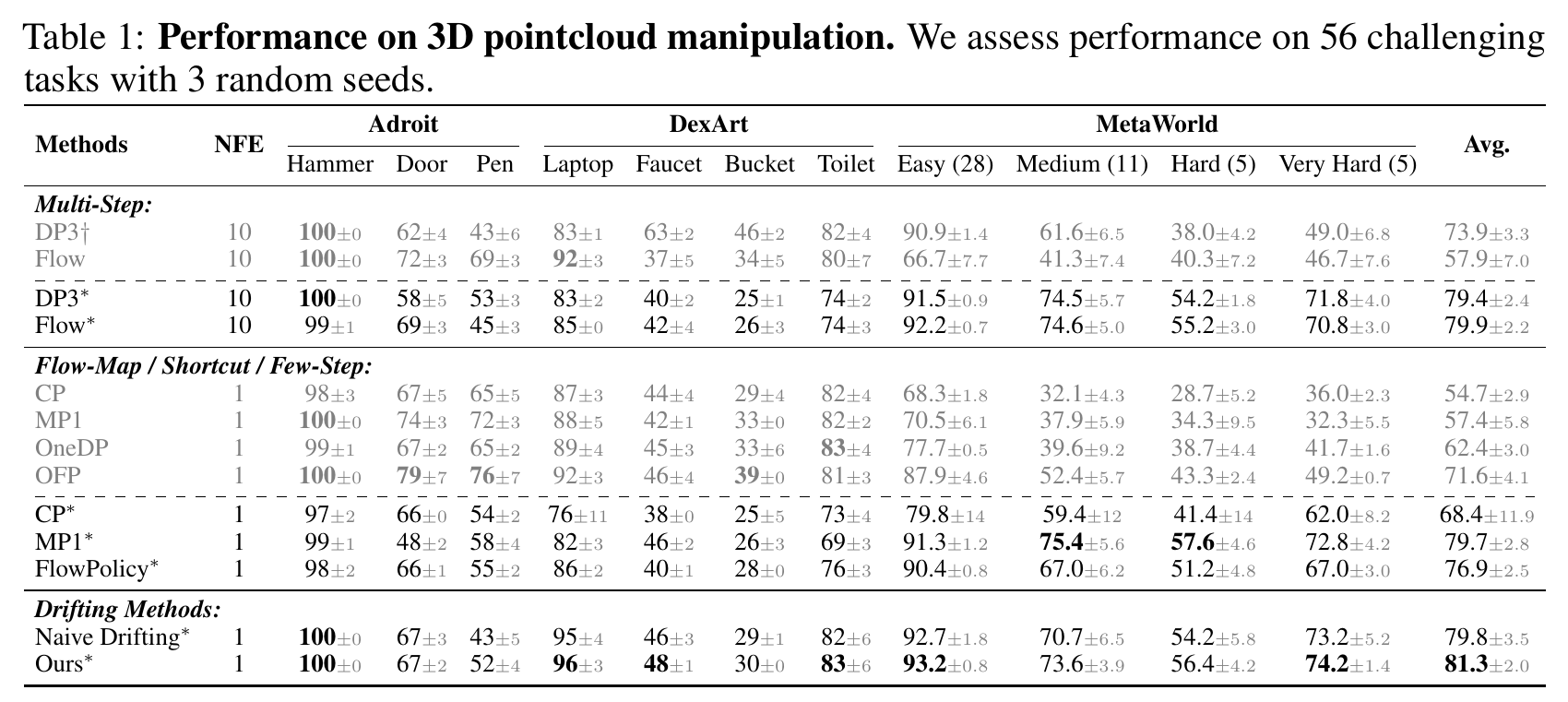
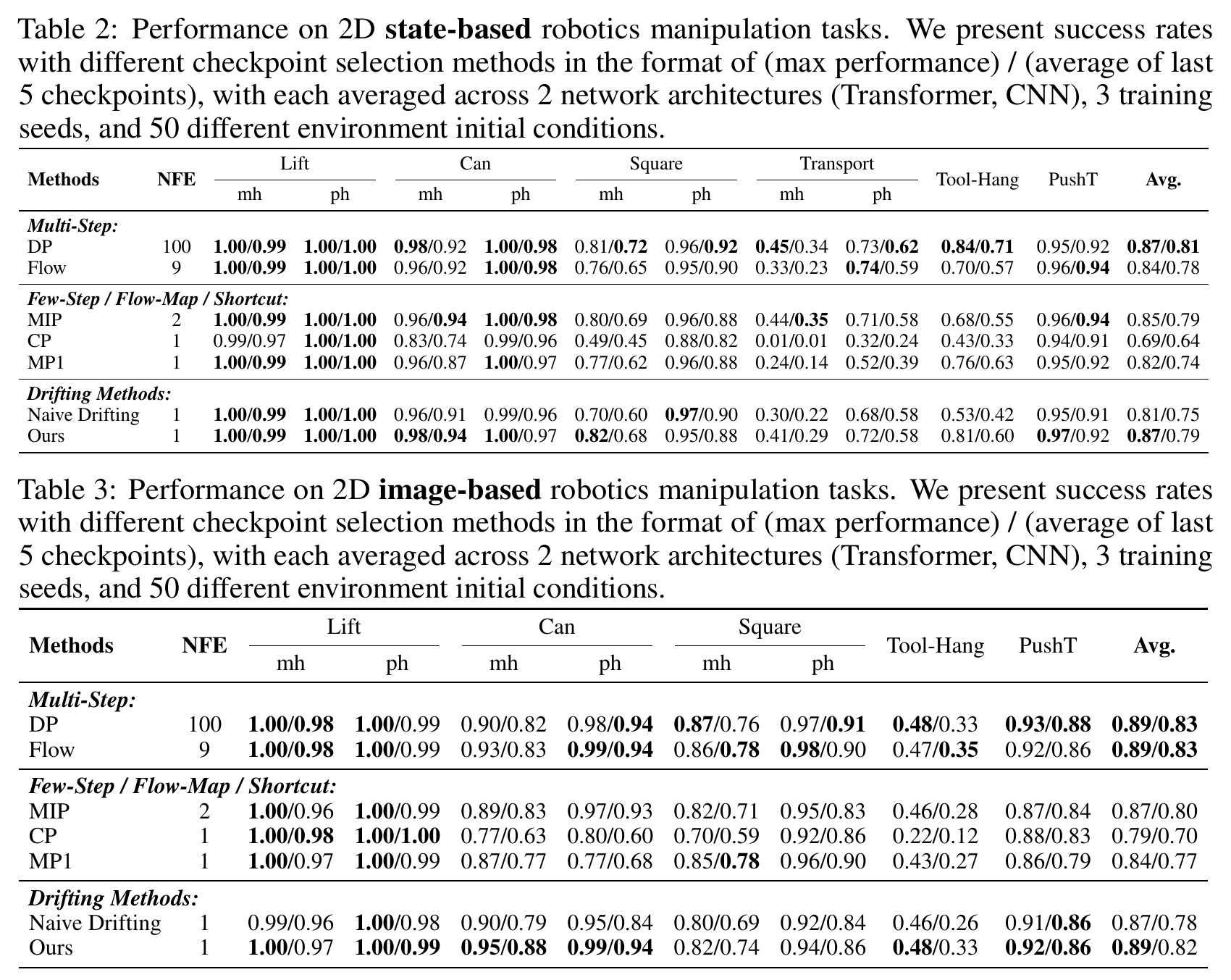
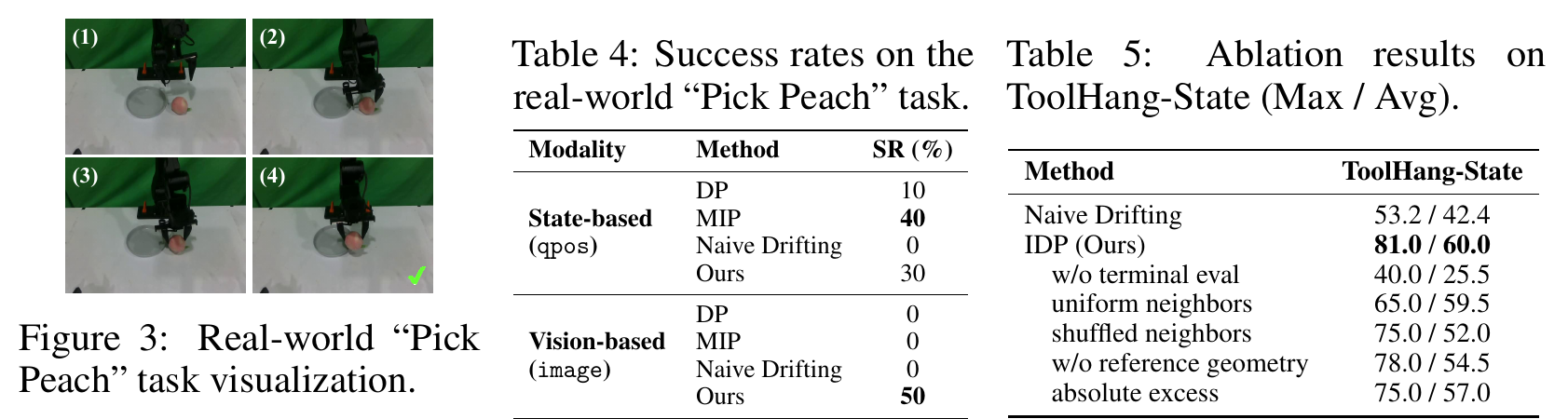
From Explicit to Implicit Drifting
Explicit drifting tries to construct corrected targets by estimating a drifting field around the current policy prediction. In behavior cloning, each condition usually supplies only one expert action, so this field degenerates into an unstable, mini-batch-sensitive signal. IDP instead reads the corrective structure directly from demonstrations: observation-similar expert actions define a conditional local geometry, which becomes the source of a one-step training correction.
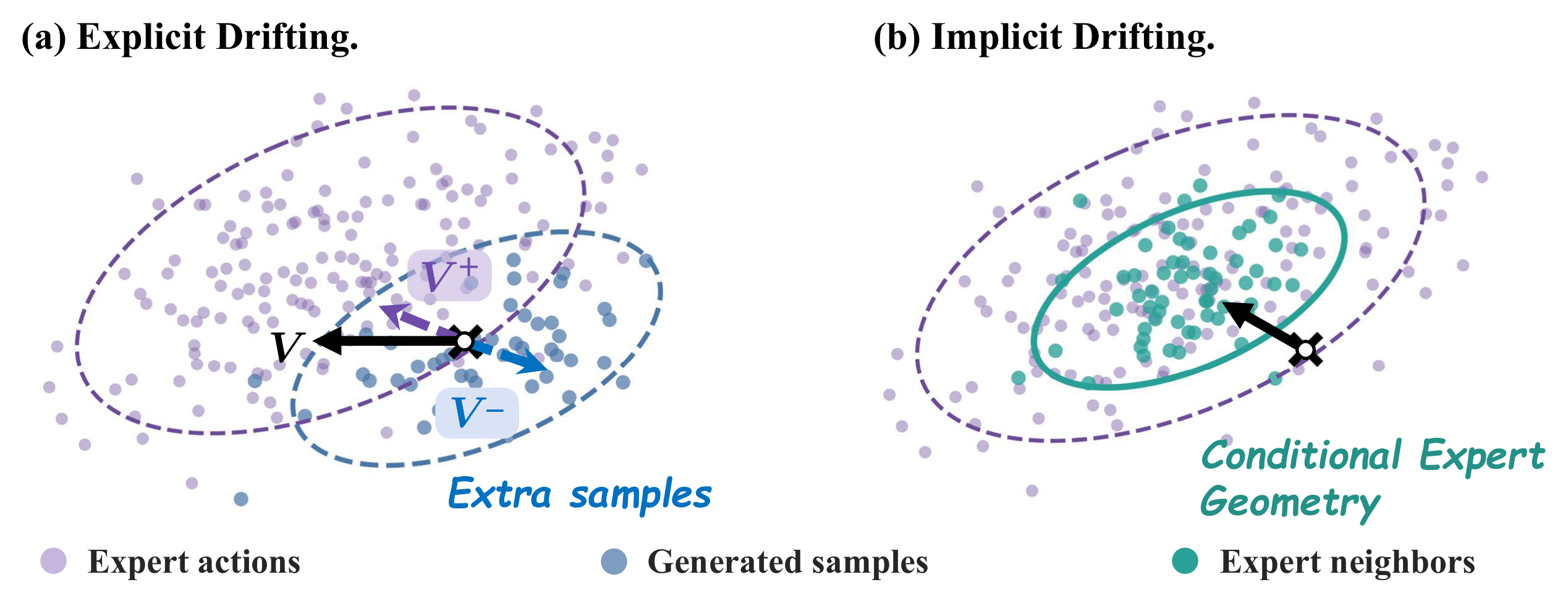
Per-observation demonstrations are too sparse to support a reliable conditional vector field.
The correction is induced by a scalar potential, not an explicit drifting vector field.
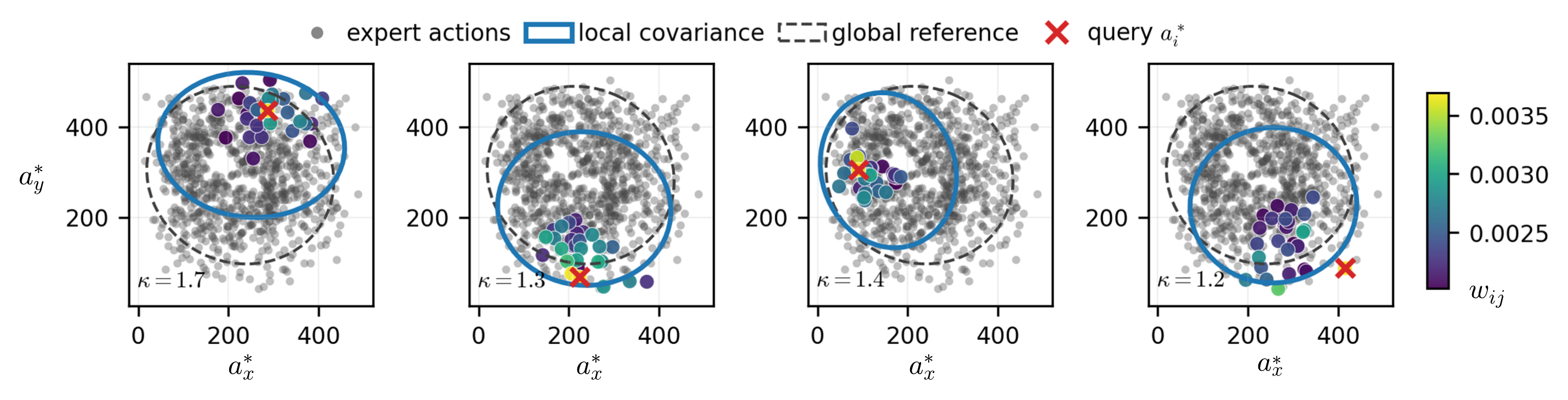
Observation-similar demonstrations identify the action directions that should be tightly controlled.